Latent Space and Contrastive Learning
Latent Space
-
Definition: Representation of compressed data
-
Data compression: process of encoding information using fewer bits than the original representation
Ekin Tiu has a Medium article about why it is called latent “space” here
-
Tasks where latent space is necessary
-
Representation learning:
-
Definition: set of techniques that allow a system to discover the representations needed for feature detection or classification from raw data
-
Latent space representation of our data must contain all the important info (features) to represent our original data input
-
-
Manifold learning (subfield of representation learning):
-
Definition: groups or subsets of data that are “similar” in some way in the latent space, that does not quite show in the higher dimensional space.
-
Manifolds just mean groups of similar data
-
-
Autoencoders and Generative Models
-
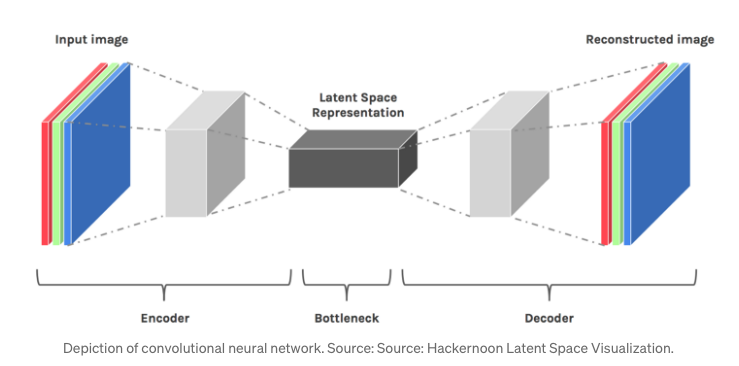
Autoencoders: a neural network that acts an identify function, that has both an encoder and a decoder
-
We need the model to compress the representation (encode) in a way that we can accurately reconstruct it (decode).
- i.e. image in image out, audio in audio out
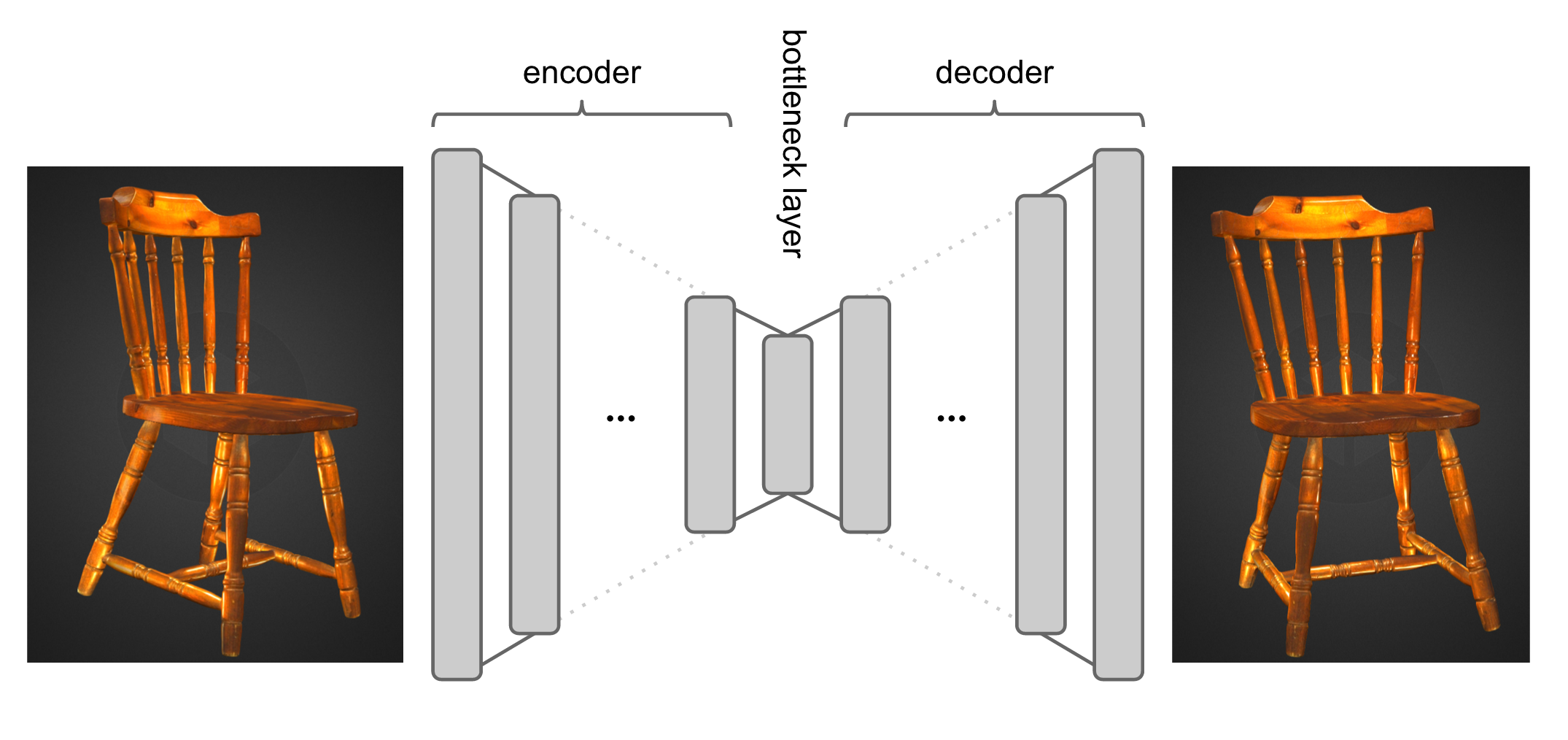
- i.e. image in image out, audio in audio out
-
Generative models: interpolate on latent space to generate “new” image
-
Interpolate: make estimations of independent variables if the independent variable takes on a value in between the range
-
Example: if chair images have 2D latent space vectors as [0.4, 0.5] and [0.45, 0.45], whereas the table has [0.6, 0.75]. Then to generate a picture that is a morph between a chair and a desk, we would sample points in latent space between the chair cluster and the desk cluster.
-
Diff between discriminative and generative:
-
Generative can generate new data instances, capture the joint probability of p(X,Y) or p(X) if Y does not exist
-
Discriminative models classifies instances into different labels. It captures p(Y X) -> given the image, how likely is it a cat?
-
-
-
-
Contrastive Learning with SimCLRv2
-
Definition: a technique that learns general features of a dataset without labels by teaching the model which data points are similar or different.
-
Happens before classification or segmentation.
-
A type of self-supervised learning. The other is non-contrastive learning.
-
Can significantly improve model performance even when only a fraction of the dataset is labeled.
-
-
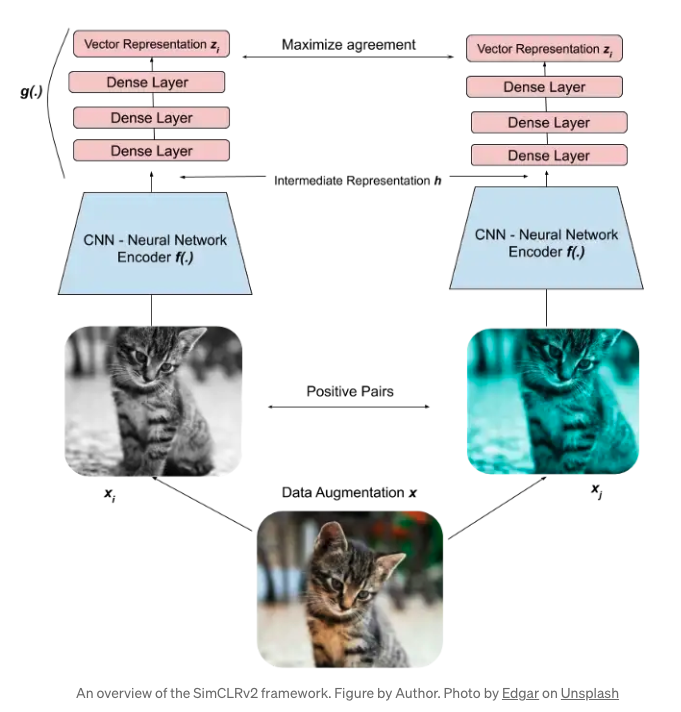
Process:
-
Data Augmentation through 2 augmentation combos (i.e. crop + resize + recolor, etc.)
-
Encoding: Feed the two augmented images into deep learning model to create vector representations.
- Goal is to train the model to output similar representations for similar images
-
Minimize loss: Maximize the similarity of the two vector representations by minimizing a contrastive loss function
-
Goal is to quantify the similarity of the two vector representations, then maximize the probability that two vector representations are similar.
- We use cosine similarity as an example to quantify similarities: the angle between the two vectors in space. The closer they are, the bigger the similarity score
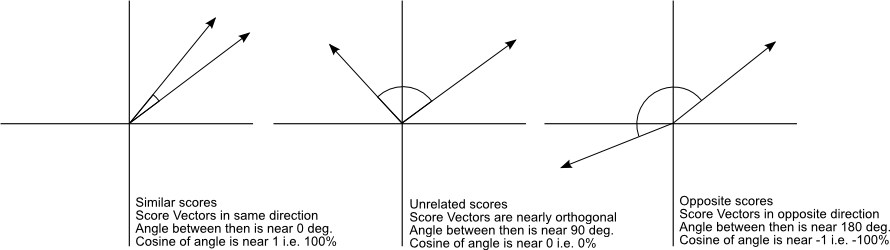
- Next compute the probability with softmax:
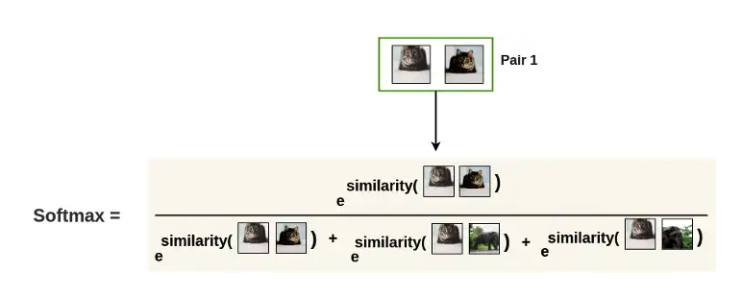
- Last we use -log() to make it a loss function so that we are minimizing this value, which corresponds to maximizing the probability that two pairs are similar
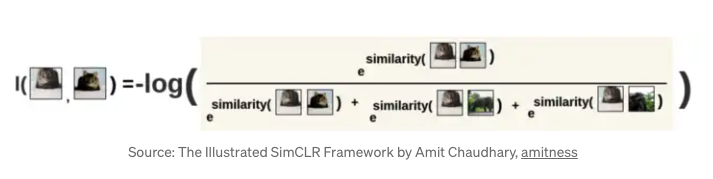
-
-